String Similarity
String Similarity functions are used to identify duplicates in datasets. Typically used in data cleansing and data quality processes, the string similarity algorithm assigns a value in the range [0,1] to identify ‘similar’ strings.
As a range value is assigned to similar strings, typo’s, errors and near matches can be identified. Whilst this can be accomplished with SQL, the code is typically inefficient, iterative and complex although this is influenced by the use case and size of the dataset. For this reason it is simpler and more efficient to use the string similarity function Teradata provides for in database processing if you want to run string similarity on data that is already on the database platform.
The syntax is relatively simple:
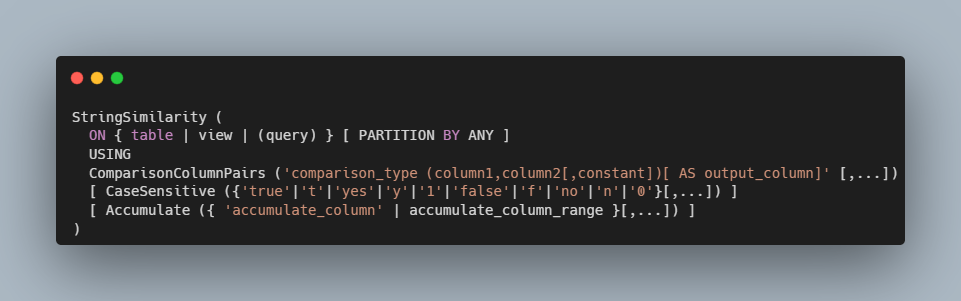
Options you can use in the function are listed in the reference document. The example I put together uses the comparison type, ‘Levenshtein distance’, so ‘LD’ in the code. You can use other types listed in the reference document or use multiple types in the same statement. ‘PARTITION BY ANY’ tell’s Teradata to let the optimizer decide how to parallelize the computation.
Here is an example you can use (link to script at the end) to explore string_similarity on Teradata.
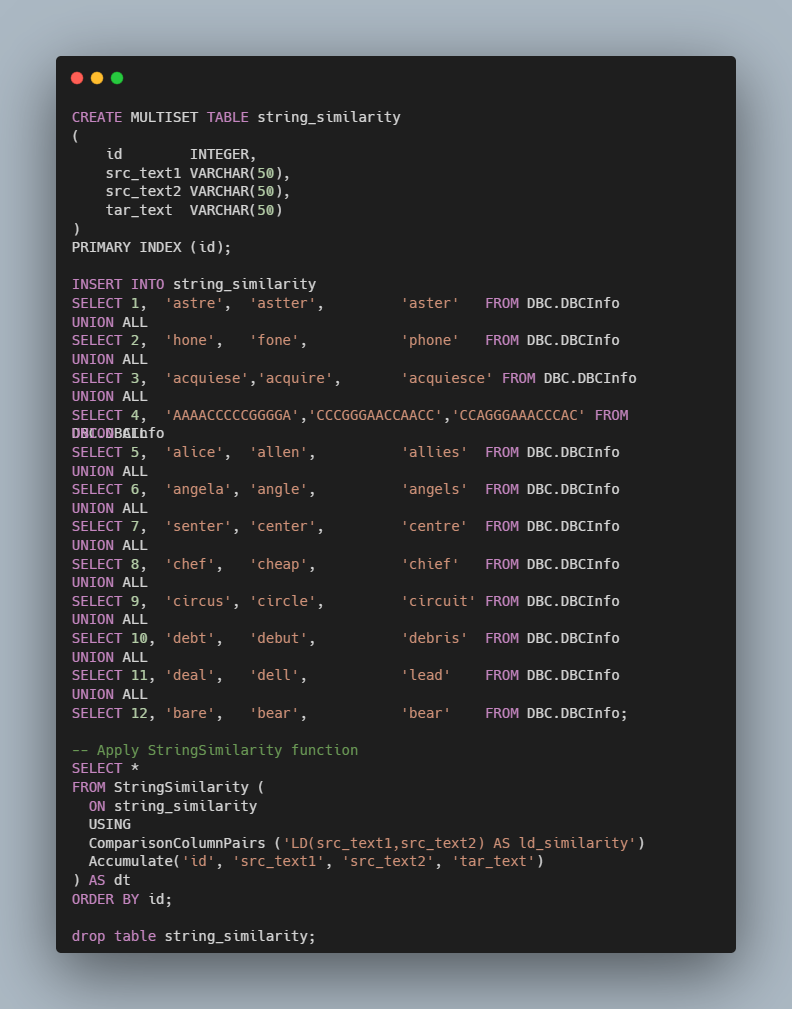

String Similarity example script output